02-Ptuh-reference-annotation
================
Kathleen Durkin
2024-09-04
- 1 Transcriptome
- 1.1 Retrieve transcriptome
fasta file
- 1.2
Database Creation
- 1.2.1 Obtain Fasta
(UniProt/Swiss-Prot)
- 1.2.2 Making the database
- 1.3 Running
Blastx
- 1.4 Joining Blast table
with annoations.
- 1.4.1 Prepping Blast
table for easy join
- 1.4.2
Could do some cool stuff in R here reading in table
Code to annotate our *P. tuahiniensis* reference files (the *P.
meandrina* transcriptome and genome) with GO information
# 1 Transcriptome
## 1.1 Retrieve transcriptome fasta file
We’ll be using the *P. meandrina* genes fasta file stored
[here](https://gannet.fish.washington.edu/acropora/E5-deep-dive/Transcripts/Pocillopora_meandrina_HIv1.genes.cds.fna).
Accessible on the `deep-dive` [genomic resources
page](https://github.com/urol-e5/deep-dive/wiki/Species-Characteristics-and-Genomic-Resources#genomic-resources).
``` bash
curl https://gannet.fish.washington.edu/acropora/E5-deep-dive/Transcripts/Pocillopora_meandrina_HIv1.genes.cds.fna \
-k \
> ../../data/Pocillopora_meandrina_HIv1.genes.cds.fna
```
Let’s check the file
``` bash
echo "First few lines:"
head -3 ../../data/Pocillopora_meandrina_HIv1.genes.cds.fna
echo ""
echo "How many sequences are there?"
grep -c ">" ../../data/Pocillopora_meandrina_HIv1.genes.cds.fna
```
## First few lines:
## >Pocillopora_meandrina_HIv1___RNAseq.g5351.t1
## ATGGGAACATCCATTTCGAAAAAACTTGAGGAGCAACAGAAAACCAAGGACGAGAAAGCCGTGGAAGAGCTGCAGATGCTGCAAGAGATGATGGTTAATAAAGTTGCCGCCGCCAGAGCAGAGATGAGGGAAAAGGCGCTCAAAGACGCTAATGTCCCGATTGTGGCGTTTGTCGACACATCAGAGAAGTATTCTGTCGACGTGTCGAACGCGCCTGATGATGCCATAACTACATCGATCAAAGAAATGTTTGGTGGAAACATCAAACAGGGTCTTGTGAGCCTCATCGGCGTGGCCCTCAACCAGTTCTTGGGAAACACTCAGGCTGGCGTAAGTGGGCAGAACGATTACCACATCGTCTTTAGCGATAACGCCCTCTTGCGAATCGATGTTATGTTTTACAAATACGAGTTTTCATCCAAAGGAGTAAAAGATGAACGTCGGAATGGGTTCTGCTACTGCACACAAGCTGCTGTTGTTGACCTCAAAAAGGTGAGCCCGGAAGTCTTGCTGTACGAGCTCACACGTACGATTGGCCAGGAAAATATTCCCGACGCAGTAAAACAGCTTCATTTAATGGCTGAATTTGGAGAGCAGTTGTACCAAGTTGTCAACGAGTTGAACACCGCTGCCGAGAAAACCCTCCCAGATTCTGACGATGGTGCTGGTCGTAAGAAACAAATAAGAAATTCAAGCCAAGAAGAGGATGATGAAGAACATGATGACTGA
## >Pocillopora_meandrina_HIv1___RNAseq.g22918.t1
##
## How many sequences are there?
## 31840
``` r
# Read FASTA file
fasta_file <- "../../data/Pocillopora_meandrina_HIv1.genes.cds.fna" # Replace with the name of your FASTA file
sequences <- readDNAStringSet(fasta_file)
# Calculate sequence lengths
sequence_lengths <- width(sequences)
# Create a data frame
sequence_lengths_df <- data.frame(Length = sequence_lengths)
# Plot histogram using ggplot2
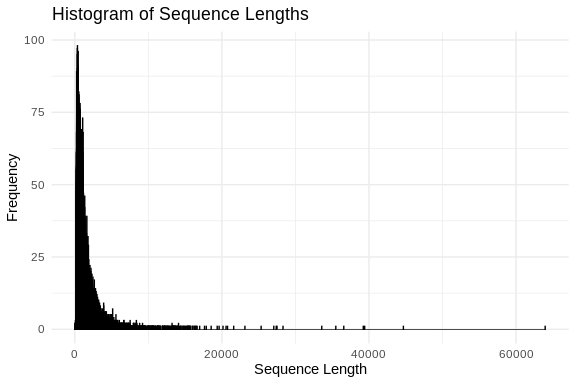
ggplot(sequence_lengths_df, aes(x = Length)) +
geom_histogram(binwidth = 1, color = "black", fill = "blue", alpha = 0.75) +
labs(title = "Histogram of Sequence Lengths",
x = "Sequence Length",
y = "Frequency") +
theme_minimal()
```
 ``` r
summary(sequence_lengths_df)
```
## Length
## Min. : 30
## 1st Qu.: 534
## Median : 957
## Mean : 1377
## 3rd Qu.: 1642
## Max. :63966
``` r
# Calculate base composition
base_composition <- alphabetFrequency(sequences, baseOnly = TRUE)
# Convert to data frame and reshape for ggplot2
base_composition_df <- as.data.frame(base_composition)
base_composition_df$ID <- rownames(base_composition_df)
base_composition_melted <- reshape2::melt(base_composition_df, id.vars = "ID", variable.name = "Base", value.name = "Count")
# Plot base composition bar chart using ggplot2
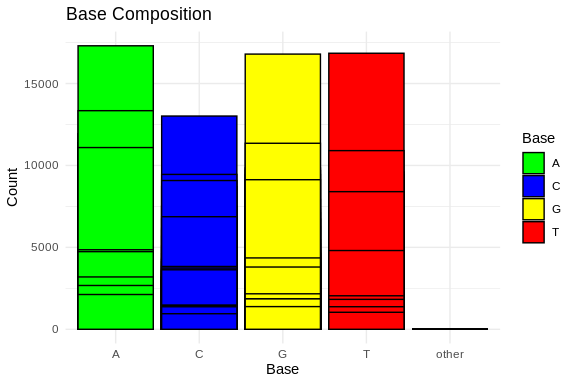
ggplot(base_composition_melted, aes(x = Base, y = Count, fill = Base)) +
geom_bar(stat = "identity", position = "dodge", color = "black") +
labs(title = "Base Composition",
x = "Base",
y = "Count") +
theme_minimal() +
scale_fill_manual(values = c("A" = "green", "C" = "blue", "G" = "yellow", "T" = "red"))
```
``` r
summary(sequence_lengths_df)
```
## Length
## Min. : 30
## 1st Qu.: 534
## Median : 957
## Mean : 1377
## 3rd Qu.: 1642
## Max. :63966
``` r
# Calculate base composition
base_composition <- alphabetFrequency(sequences, baseOnly = TRUE)
# Convert to data frame and reshape for ggplot2
base_composition_df <- as.data.frame(base_composition)
base_composition_df$ID <- rownames(base_composition_df)
base_composition_melted <- reshape2::melt(base_composition_df, id.vars = "ID", variable.name = "Base", value.name = "Count")
# Plot base composition bar chart using ggplot2
ggplot(base_composition_melted, aes(x = Base, y = Count, fill = Base)) +
geom_bar(stat = "identity", position = "dodge", color = "black") +
labs(title = "Base Composition",
x = "Base",
y = "Count") +
theme_minimal() +
scale_fill_manual(values = c("A" = "green", "C" = "blue", "G" = "yellow", "T" = "red"))
```
 ``` r
# Count CG motifs in each sequence
count_cg_motifs <- function(sequence) {
cg_motif <- "CG"
return(length(gregexpr(cg_motif, sequence, fixed = TRUE)[[1]]))
}
cg_motifs_counts <- sapply(sequences, count_cg_motifs)
# Create a data frame
cg_motifs_counts_df <- data.frame(CG_Count = cg_motifs_counts)
# Plot CG motifs distribution using ggplot2
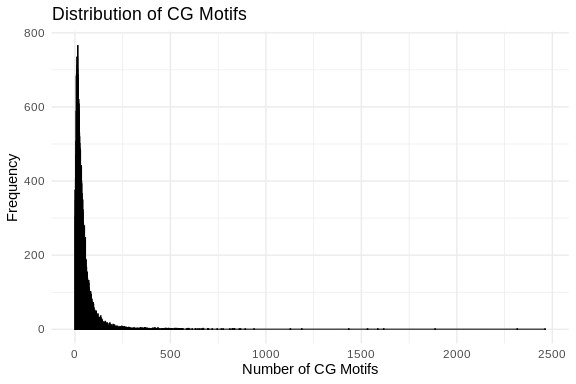
ggplot(cg_motifs_counts_df, aes(x = CG_Count)) +
geom_histogram(binwidth = 1, color = "black", fill = "blue", alpha = 0.75) +
labs(title = "Distribution of CG Motifs",
x = "Number of CG Motifs",
y = "Frequency") +
theme_minimal()
```
``` r
# Count CG motifs in each sequence
count_cg_motifs <- function(sequence) {
cg_motif <- "CG"
return(length(gregexpr(cg_motif, sequence, fixed = TRUE)[[1]]))
}
cg_motifs_counts <- sapply(sequences, count_cg_motifs)
# Create a data frame
cg_motifs_counts_df <- data.frame(CG_Count = cg_motifs_counts)
# Plot CG motifs distribution using ggplot2
ggplot(cg_motifs_counts_df, aes(x = CG_Count)) +
geom_histogram(binwidth = 1, color = "black", fill = "blue", alpha = 0.75) +
labs(title = "Distribution of CG Motifs",
x = "Number of CG Motifs",
y = "Frequency") +
theme_minimal()
```
 ## 1.2 Database Creation
### 1.2.1 Obtain Fasta (UniProt/Swiss-Prot)
``` bash
cd ../../data
curl -O https://ftp.uniprot.org/pub/databases/uniprot/current_release/knowledgebase/complete/uniprot_sprot.fasta.gz
mv uniprot_sprot.fasta.gz uniprot_sprot_r2023_04.fasta.gz
gunzip -k uniprot_sprot_r2023_04.fasta.gz
```
### 1.2.2 Making the database
``` bash
/home/shared/ncbi-blast-2.11.0+/bin/makeblastdb \
-in ../../data/uniprot_sprot_r2023_04.fasta \
-dbtype prot \
-out ../../blastdb/uniprot_sprot_r2023_04
```
## 1.3 Running Blastx
``` bash
/home/shared/ncbi-blast-2.11.0+/bin/blastx \
-query ../../data/Pocillopora_meandrina_HIv1.genes.cds.fna \
-db ../../blastdb/uniprot_sprot_r2023_04 \
-out ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx.tab \
-evalue 1E-20 \
-num_threads 40 \
-max_target_seqs 1 \
-outfmt 6
```
``` bash
echo "First few lines:"
head -2 ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx.tab
echo "Number of lines in output:"
wc -l ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx.tab
```
## First few lines:
## Pocillopora_meandrina_HIv1___RNAseq.g27719.t1 sp|Q7ZT01|PSF3_XENLA 46.465 198 106 0 19 612 7 204 3.67e-66 205
## Pocillopora_meandrina_HIv1___RNAseq.g14270.t1 sp|P55112|NAS4_CAEEL 39.548 177 102 2 298 825 74 246 1.16e-38 141
## Number of lines in output:
## 18087 ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx.tab
## 1.4 Joining Blast table with annoations.
### 1.4.1 Prepping Blast table for easy join
``` bash
tr '|' '\t' < ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx.tab \
> ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx_sep.tab
head -1 ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx_sep.tab
```
## Pocillopora_meandrina_HIv1___RNAseq.g27719.t1 sp Q7ZT01 PSF3_XENLA 46.465 198 106 0 19 612 7 204 3.67e-66 205
### 1.4.2 Could do some cool stuff in R here reading in table
``` r
bltabl <- read.csv("../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx_sep.tab", sep = '\t', header = FALSE)
spgo <- read.csv("https://gannet.fish.washington.edu/seashell/snaps/uniprot_table_r2023_01.tab", sep = '\t', header = TRUE)
datatable(head(bltabl), options = list(scrollX = TRUE, scrollY = "400px", scrollCollapse = TRUE, paging = FALSE))
```
``` r
datatable(head(spgo), options = list(scrollX = TRUE, scrollY = "400px", scrollCollapse = TRUE, paging = FALSE))
```
``` r
datatable(
left_join(bltabl, spgo, by = c("V3" = "Entry")) %>%
select(V1, V3, V13, Protein.names, Organism, Gene.Ontology..biological.process., Gene.Ontology.IDs)
)
```
## 1.2 Database Creation
### 1.2.1 Obtain Fasta (UniProt/Swiss-Prot)
``` bash
cd ../../data
curl -O https://ftp.uniprot.org/pub/databases/uniprot/current_release/knowledgebase/complete/uniprot_sprot.fasta.gz
mv uniprot_sprot.fasta.gz uniprot_sprot_r2023_04.fasta.gz
gunzip -k uniprot_sprot_r2023_04.fasta.gz
```
### 1.2.2 Making the database
``` bash
/home/shared/ncbi-blast-2.11.0+/bin/makeblastdb \
-in ../../data/uniprot_sprot_r2023_04.fasta \
-dbtype prot \
-out ../../blastdb/uniprot_sprot_r2023_04
```
## 1.3 Running Blastx
``` bash
/home/shared/ncbi-blast-2.11.0+/bin/blastx \
-query ../../data/Pocillopora_meandrina_HIv1.genes.cds.fna \
-db ../../blastdb/uniprot_sprot_r2023_04 \
-out ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx.tab \
-evalue 1E-20 \
-num_threads 40 \
-max_target_seqs 1 \
-outfmt 6
```
``` bash
echo "First few lines:"
head -2 ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx.tab
echo "Number of lines in output:"
wc -l ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx.tab
```
## First few lines:
## Pocillopora_meandrina_HIv1___RNAseq.g27719.t1 sp|Q7ZT01|PSF3_XENLA 46.465 198 106 0 19 612 7 204 3.67e-66 205
## Pocillopora_meandrina_HIv1___RNAseq.g14270.t1 sp|P55112|NAS4_CAEEL 39.548 177 102 2 298 825 74 246 1.16e-38 141
## Number of lines in output:
## 18087 ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx.tab
## 1.4 Joining Blast table with annoations.
### 1.4.1 Prepping Blast table for easy join
``` bash
tr '|' '\t' < ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx.tab \
> ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx_sep.tab
head -1 ../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx_sep.tab
```
## Pocillopora_meandrina_HIv1___RNAseq.g27719.t1 sp Q7ZT01 PSF3_XENLA 46.465 198 106 0 19 612 7 204 3.67e-66 205
### 1.4.2 Could do some cool stuff in R here reading in table
``` r
bltabl <- read.csv("../output/02-Ptuh-reference-annotation/Pocillopora_meandrina_HIv1-uniprot_blastx_sep.tab", sep = '\t', header = FALSE)
spgo <- read.csv("https://gannet.fish.washington.edu/seashell/snaps/uniprot_table_r2023_01.tab", sep = '\t', header = TRUE)
datatable(head(bltabl), options = list(scrollX = TRUE, scrollY = "400px", scrollCollapse = TRUE, paging = FALSE))
```
``` r
datatable(head(spgo), options = list(scrollX = TRUE, scrollY = "400px", scrollCollapse = TRUE, paging = FALSE))
```
``` r
datatable(
left_join(bltabl, spgo, by = c("V3" = "Entry")) %>%
select(V1, V3, V13, Protein.names, Organism, Gene.Ontology..biological.process., Gene.Ontology.IDs)
)
```